今天pycon2019第一天,好多topic都好有趣!如果覺得有什麼好玩的或想進階想專研,歡迎聯繫有機會一起研究XD好哩接下來要來介紹強化學習最經典的方法:Q-learning,Q代表品質(quality)。
Q-learning是個狀態(state)-動作(action)的互動。假設某天跟皮卡丘的互動會有兩個情境:
1.看皮卡丘可愛捏臉,皮卡丘疼了不開心,便會使出民間電療法-十萬伏特~~~
2.看皮卡丘可愛摸摸頭,皮卡丘開心了,則好感值upup。
阿這不就培養遊戲嗎?養賤兔、牧場物語、模擬人生,概念類似挺直覺的。
這邊有兩點要先說前提:
第一點簡單你可以想像,每當我們對事情有多個選擇,我們總是想挑選最好的、最棒的、能利益最大化的,而且每次的選擇我們都是這樣。
第二點呢,我們了解到如果皮卡丘的心靈是健康的,它對外在的任何刺激都會有正常反應對吧?但在這我們先假設無論對皮卡丘做了什麼(親他or抱他or捏他),皮卡丘在接受到你的動作後,會給個即時反應(reward),但後面就恢復淡定了。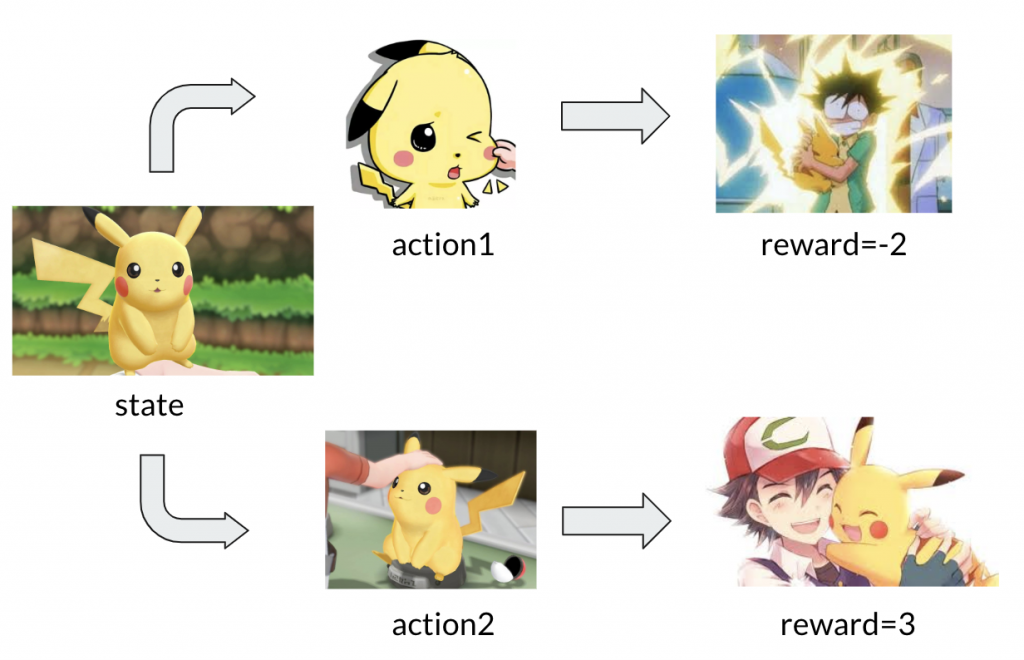
1.狀態性質一樣都是無差異,那state1(淡定狀態)=state2(淡定狀態)=state3(淡定狀態)...
2.動作兩種,捏臉(action1)跟摸頭(action2)
這裡假設我們決策的次數有兩回合,則這裡我們可以用表格去說明: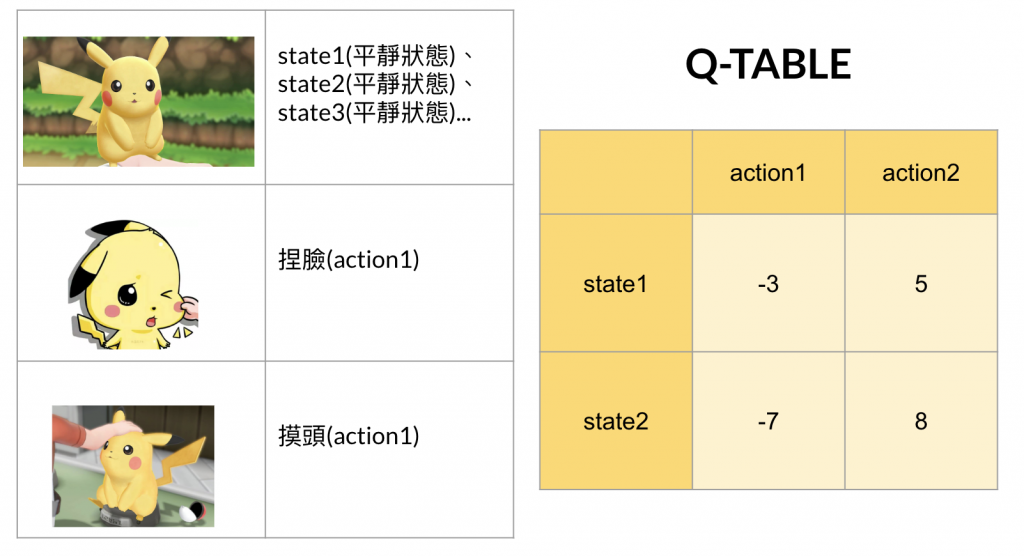
補充:Q-table是根據當前狀態(state)跟動作(action)輸出值,這種以值做決策的我們稱價值函數(value function)。另外一種則是以取最大機率值為依據,我們稱策略函數(policy function),策略函數我們未來有機會會提到。
看到這一定會有疑問,皮卡丘不會只有淡定狀態呀(就算是凌波零也是會微笑的!),他還有生悶氣或很開心的狀態。沒錯~就跟遊戲畫面一樣,螢幕畫面一定是動態的,但為了這章以及下章講解Q-learning,我們暫時先把這個狀態暫定不變。好了今天先掰拉,明天會有Q-learning的更多講解以及它的值實際是什麼~

